# 一、简介
MongoDB是一个开源、高性能、无模式(没有确定的列)的文档型数据库,设计之初是为了简化开发和方便扩展,是NoSQL数据库产品中的一种。是最像关系型数据库的非关系型数据库。
它支持的数据库结构非常松散,是一种类似JSON格式的BSON,所以它既可以存储比较复杂的数据类型,又相当的灵活。
MongoDB中的记录是一个文档,它是一个由记录和键值对(filed:value)组成的数据结构。MongoDB文档类似于JSON对象,即一个文档可以认为就是一个对象。字段的数据类型是字符型,它的值除了使用一些类型外,还可以包括其他文档、普通数组和文档数组。
# 体系结构
关系型数据库与MongoDB的对比
| SQL术语/概念 | MongoDB | 描述 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | 表连接,MongoDB不支持 | |
| 嵌入文档 | MongoDB通过嵌入式文档来替代多表连接 | |
| primary key | primary key | 主键,MongoDB自动将_id字段设置为主键 |
# 数据模型
MongoDB的最小存储单位是文档(document)对象。
文档对象对应关系型数据库中的行。数据在MongoDB中是以BSON(Binary-JSON)文档的格式存储在磁盘上的。
BSON(Binary Serizlized Document Format)是一种类JSON的二进制形式的存储格式,简称Binary JSON。跟JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的数据类型,如Date、BinData。
BSON采用类似于C语言结构体的名称、对表示方法,支持内嵌的文档对象和数组对象,具有轻量级、可遍历性、高效性的三个特点,可以有效地描述非结构化数据和结构化数据。优点是灵活性高,但缺点是空间利用率不是很理想。
BSON中,除了支持基本的JSON类型(string、integer、boolean、double、null、array、object)外,还有特殊的数据类型,如:date、object id、binary data、regular expression、code。
BSON数据类型:
| 数据类型 | 描述 | 举例 |
|---|---|---|
| 字符串 | UTF-8字符串都可以表示为字符串类型的数据 | {"x":"type"} |
| 对象id | 对象id是文档的12字节的唯一ID | {"X":ObjectId()} |
| 布尔值 | true、false | {"x":true} |
| 数组 | 值的集合或列表可以表示的数组 | {"x":["a":"b":"c"]} |
| 32位整数 | 类型不可用。JavaScript仅支持64位浮点数,所以32位整数会被 | shell是不支持该类型的,shell中默认会转换成64位浮点数 |
| 64位整数 | 不支持这个类型。shell会使用一个特殊的内嵌文档来显示64位 | shell是不支持该类型的,shell中默认会转换成64 |
| 64位浮点数 | shell中的数字就是这一种类型 | {"x":3.14159,"y":3} |
| null | 表示空值或者未定义的对象 | {"x":null} |
| undefined | 文档中也可以使用未定义类型 | {"x":undefined} |
| 符号 | shell不支持,shell会将数据库中的符号类型的数据自动换成字符串 | |
| 正则表达式 | 文档中可以包含正则表达式,采用JavaScript的正则表达式语法 | {"x":/type/i} |
| 代码 | 文档中可以包含JavaScript代码 | {"x":function(){}} |
| 二进制数据 | 二进制数据可以由任意字节的串组成,不过shell中无法使用 | |
| 最大值/最小值 | BSON包括一个特殊类型,表示可能的最大值。shell中没有这个类型 |
shell默认使用64位浮点型数值。对于整型值,可以使用
NumberInt(4字节符号整数)或NumberLong(8字节符号整数),如{"x":NumberInt("3")}、{"x":NumberLong("3")}
# 特点
- 高性能
- 高可用
- 高扩展
- 丰富的查询支持
- 无模式(动态模式)、灵活的文档模型
# 二、安装部署
这里先介绍单机部署
# windows系统
下载安装包
MongoDB提供了可用于32位和64位系统的预编译二进制包。官网下载社区版 (opens new window),On-Premises(内部部署):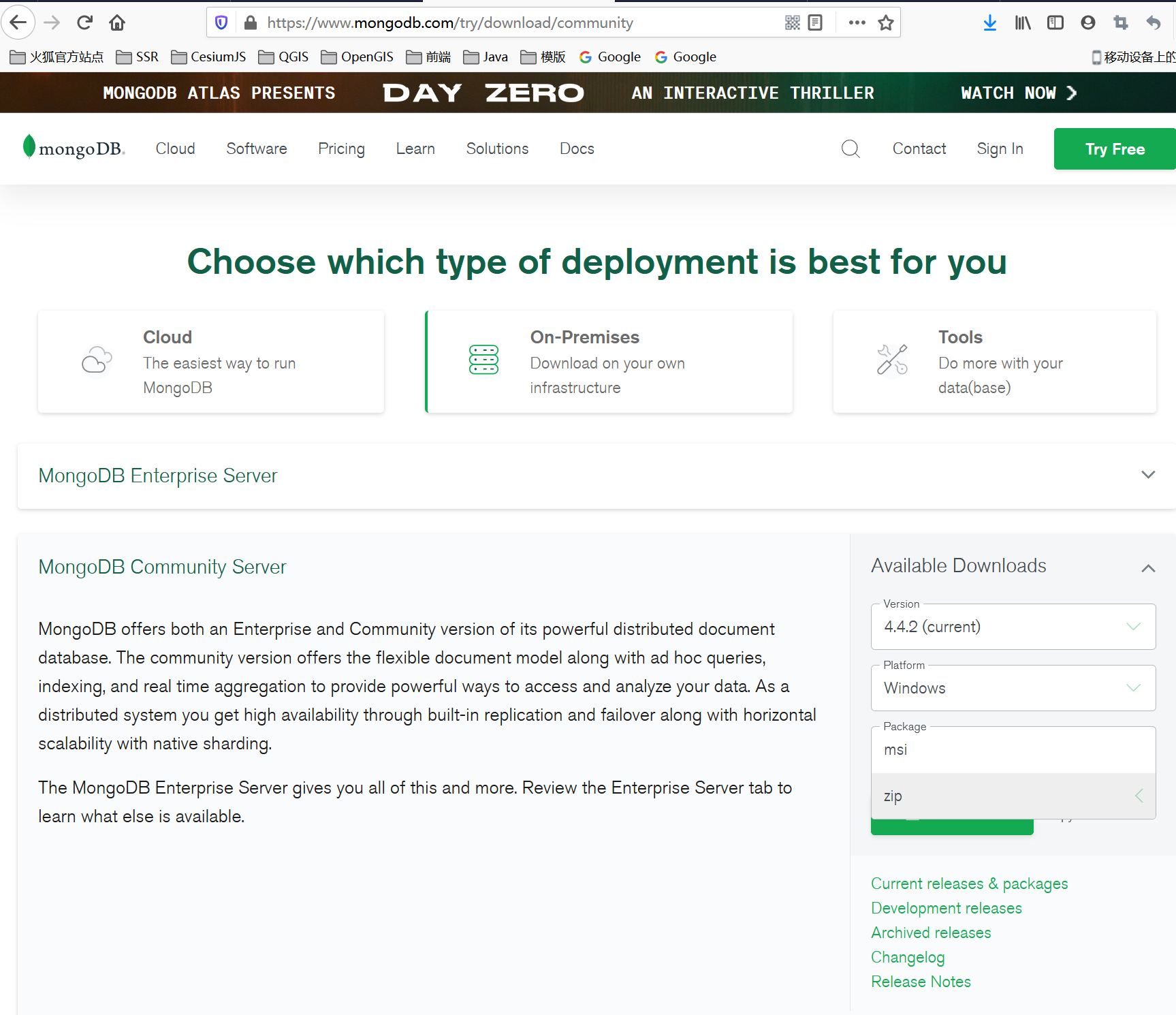
我们选择下载
zip包格式的压缩包。MongoDB 的版本命名规范如:x.y.z;
y为奇数时表示当前版本为开发版,如:1.5.2、4.1.13;
y为偶数时表示当前版本为稳定版,如:1.6.3、4.0.10;
z是修正版本号,数字越大越好。
解压安装启动
将压缩包解压到一个目录中,手动创建一个目录用于存放数据文件,如
data/db启动方式有两种:
在
bin目录下,打开cmd命令行,输入命令mongod --dbpath=..\data\db1这样
MongoDB会被启动,默认端口是27017,如果需要修改端口可以添加--port参数来指定端口。如果缺少
vcruntime140_1.dll文件会出现下面的错误,解决方式是从网上下载该文件复制到C:\Windows\System32目录下就可以。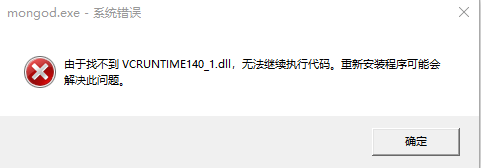
使用配置文件的方式启动服务
在解压的目录下创建
config文件夹,并在该目录下新建mongod.conf文件,内容如下:storage: dbPath: C:\D\mongodb-win32-x86_64-windows-4.4.2\data\db1
2详细配置文件和配置项。请参考官方文档 (opens new window)。
注意:
yml配置文件中不能使用tab键分割字段配置文件中如果使用双引号,比如路径地址,自动会将双引号的内容转义。如果不转义,则会报错,解决方法是:
- 将
\换成/或\\ - 如果路径中没有哦空格,则无需加引号
启动命令:
mongod -f ../config/mongod.conf 或 mongod --config ../config/mongod.conf1
2
3更多参数配置:
systemLog: #MongoDB发送所有日志输出到的目的地。指定file或syslog。 #如果指定了file,还必须指定systemLog.path。 destination: file path: "/var/log/mongodb/mongod.log" #每次启动后输出的日志追加到上一次的日志文件中 logAppend: true storage: journal: #启用或禁用持久性日志,以确保数据文件保持有效和可恢复。 #此选项仅在指定存储时适用。dbPath设置。mongod默认启用日志记录。 enabled: true processManagement: #启用后台运行mongos或mongod进程的守护模式 fork: true net: #主机名和/或IP地址和/或完整的Unix域套接字路径,mongos或mongod应该在其上监听客户端连接。 #你可以将mongos或mongod附加到任何接口。要绑定到多个地址,请输入以逗号分隔的值列表。 bindIp: 127.0.0.1 port: 27017 setParameter: enableLocalhostAuthBypass: false1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22- 将
# Shell连接(mongo命令)
在命令提示符输入mongo命令完成登陆
monogo
或
mongo --host=127.0.0.1 --port=27017
2
3
查看已存在的数据库
show database
退出mongodb
exit
MongoDB JavaScript shell 是一个基于JavaScript的解释器,所以支持JS程序
# Compass图形化界面客户端
MongoDB Compass (opens new window)是MongoDB数据库的图形化管理工具。可以下载zip压缩版本,解压后双击MongoDBCompass.exe运行。
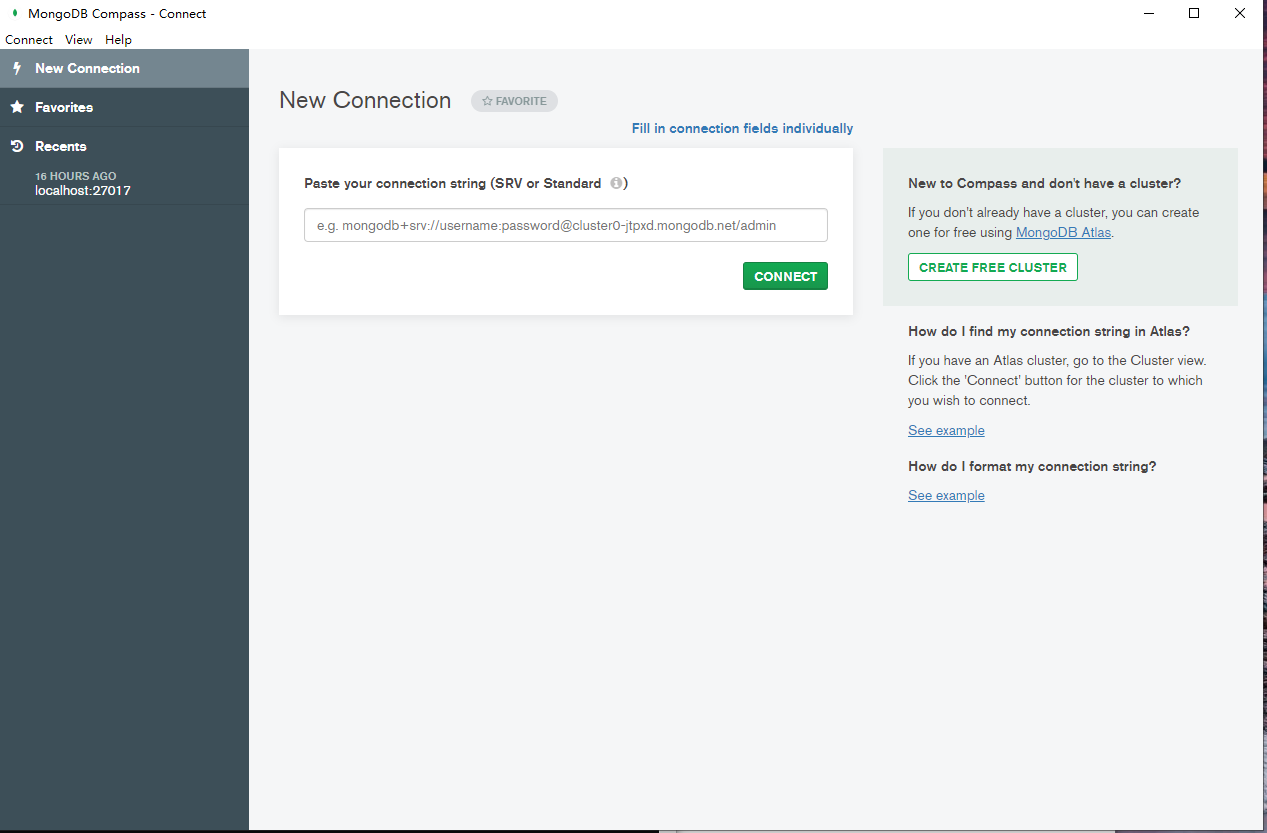
标准的connection-string (opens new window)格式:
mongodb://[username:password@]host1[:port1][,...hostN[:portN]][/[defaultauthdb][?options]]示例:
mongodb://192.168.0.152:27017
# Linux系统
在linux中部署一个单机的MongoDB,作为生产环境下使用。安装步骤跟windows下的差不多:
下载压缩包,选择
tgz压缩包的形式。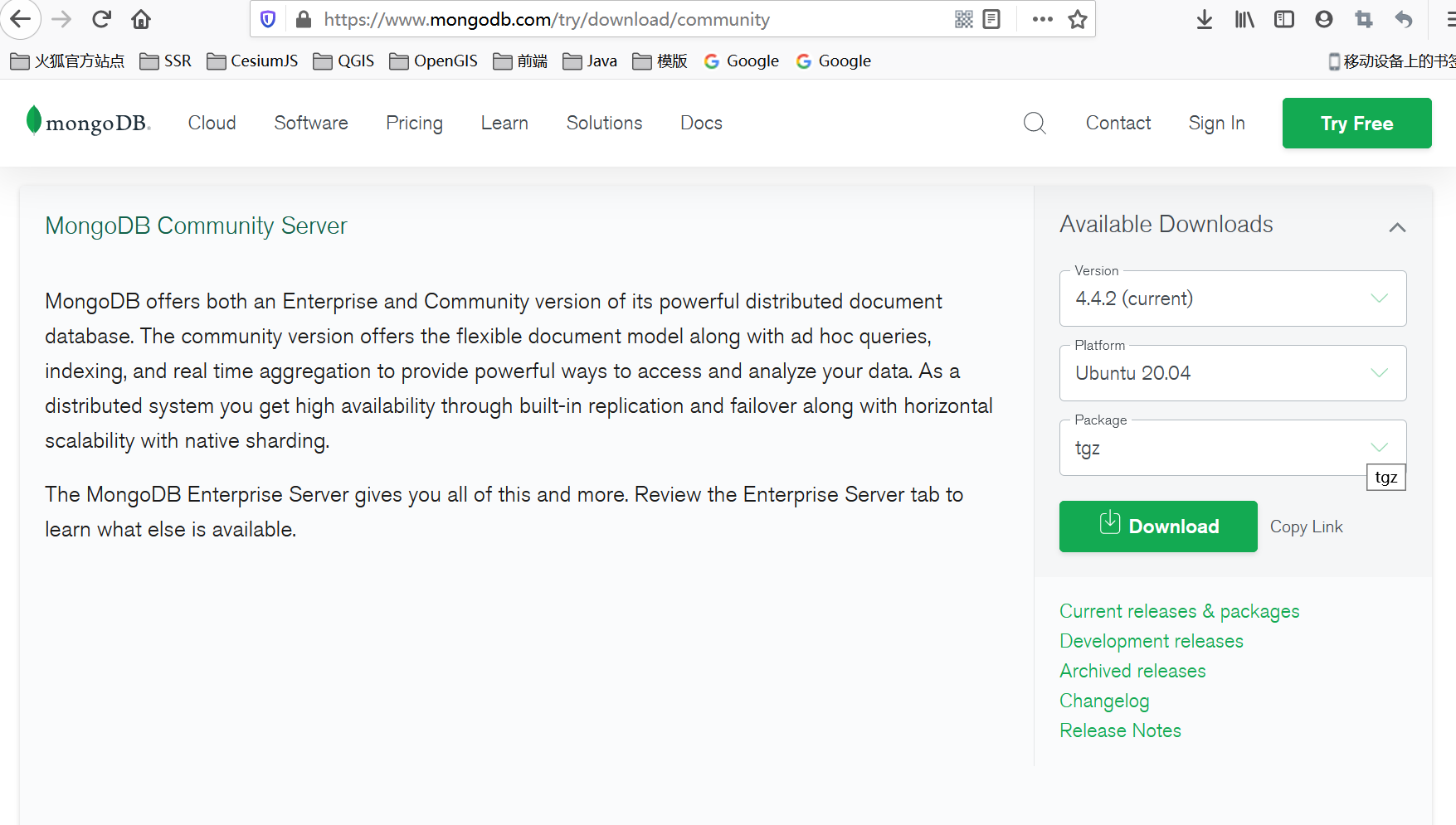
上传压缩包至
linux上,解压tar -xvf mongodb-linux-x86_64-ubuntu2004-4.4.2.tgz1将解压后的文件移动到指定的目录中
sudo mv mongodb-linux-x86_64-ubuntu2004-4.4.2 /usr/local/mongodb1创建日志和数据的存储目录
#数据存储目录 sudo mkdir -p /mongodb/single/data/db #日志目录 sudo mkdir -p /mongodb/single/log1
2
3
4
5创建启动配置文件
#查看配置参数 /usr/local/mongodb/bin/mongod --help #新建配置文件 vi /mongodb/single/mongod.conf1
2
3
4
5systemLog: destination: file path: "/home/qiusj/.local/mongodb/singlesite/log/mongodd.log" logAppend: true storage: dbPath: "/home/qiusj/.local/mongodb/singlesite/data/db" journal: enabled: true net: #添加本机在局域网内的ip bindIp: 127.0.0.1,192.168.0.152 port: 27017 setParameter: enableLocalhostAuthBypass: false processManagement: fork: true1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16折腾的比较久,发现路径有问题(应该是没有权限,打不开文件)。换了路径解决问题。
启动
MongoDB服务/usrqiusj@u20:~$ /usr/local/mongodb/bin/mongod -f /home/qiusj/.local/mongodb/singlesite/mongod.conf about to fork child process, waiting until server is ready for connections. forked process: 447853 child process started successfully, parent exiting1
2
3
4通过进程来查看服务是否启动:
qiusj@u20:~$ ps -ef|grep mongod qiusj 447853 1 0 15:16 ? 00:00:01 /usr/local/mongodb/bin/mongod -f /home/qiusj/.local/mongodb/mongod.conf1
2使用
mongo命令和compass工具连接外部链接需要设置防火墙,开放端口
#ubuntu使用的是ufw,status查看ufw防火墙的状态,allow允许扣个端口 sudo ufw status # 查看防火墙状态 sudo ufw allow 270171
2
3关闭服务
关闭服务有两种方式:
快速关闭:使用
kill命令直接杀死进程#通过进程编号关闭节点 kill -2 进程号1
2标准关闭:通过
mongo个客户端中的shutdownServer命令来关闭服务#客户端登录服务,注意,这里通过localhost登录,如果需要远程登录,必须先登录认证才行。 mongo --port 27017 #切换到admin库 use admin #如果不是admin数据库,则会报如下错误 shutdown command only works with the admin database; try 'use admin' #关闭服务 db.shutdownServer()1
2
3
4
5
6
7
8
9
10
11
# 数据修复
如果出现数据损坏的情况,可以通过下面操作进行修复:
删除lock文件
#删除数据目录下面的`.lock`文件 rm -f /data/db/*.lock1
2修复数据
/usr/local/mongdb/bin/mongod --repair --dbpath=/mongodb/single/data/db1
# 三、基本命令
# 数据库操作
#选择和创建数据:use 数据库名称
use testdb
#查看有权限查看的所有数据库,磁盘中已经持久化了的数据库
show dbs
或
show databases
#查看当前数据库
db
#删除数据库
db.dropDatabase()
2
3
4
5
6
7
8
9
10
11
12
13
如果数据库不存在则会自动创建。自动创建的在没有集合前(空数据库)是存在内存中的。
默认的数据库是
test,如果没有选择数据库,集合将存放在test数据库中
数据库名称的命名规范,必须是满足以下条件的任意UTF-8编码的字符串。
- 不能是空字符串("")
- 不得含有特殊字符(空格、$、/、\、\0)
- 全小写
- 最多64字节
三个默认数据库的特殊作用:
admin:从权限的角度,这是root数据库,要是将一个用户添加到这个数据库,这个用户将自动继承所有数据库的权限。一些特定的服务器端命令也只能从这个数据库运行,比如列出所有的数据库或关闭服务器。local:这个数据库中的数据永远不会被复制,可以用来存储限于本地单台服务器的任意集合。config:当Mongo用于分片设置时,config数据库在内部使用,用于保存分片的相关信息。
# 集合操作
集合,类似于关系型数据库中的表。可以显示创建,也可以隐式创建。
#创建名为article的集合
db.createCollection("article")
#查看当前库中的集合(表)
show collections
或
show tables
#删除集合,语法:db.集合.drop(),删除成功会返回true
db.article.drop()
2
3
4
5
6
7
8
9
10
集合的命名规范:
- 不能是空字符串""。
- 不能是空字符(\0)结尾的字符串
- 不能是以
system.开头,因为这是给系统集合保留的前缀 - 不能含有保留字符
集合的隐式创建:
当向一个集合插入一个文档的时候,如果集合不存在,则会自动创建集合(这是最常用的方式)。
# 文档的CRUD
文档document的数据结构和JSON基本一样。所有存储在集合中的数据都是BSON格式。
# 插入
文档的插入的方法有insert()、save()、insertMany()。
insert方法的语法:
db.collection.insert(
<document or array of documents>,
{
writeConcern:<document>,
ordered:<boolean>
}
)
2
3
4
5
6
7
参数列表:
| 参数 | 类型 | 说明 |
|---|---|---|
doucment | document 或document 数组 | 要插入到集合中的文档或文档数组 |
writeConcern | document | Optional. A document expressing the write concern (opens new window). Omit to use the default write concern. See Write Concern (opens new window). Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern (opens new window). |
ordered | boolean | 可选。如果为真,则按顺序插入数组中的文档,如果其中一个文档出现错误,MongoDB将返回而不处理数组中的其余文档。如果为假,则执行无序插入,如果其中一个文档出现错误,则继续处理 |
示例:
> use meface
switched to db meface
> db
meface
> show collections
article
> db.article.insert({
"articleid": "100000",
"content": "今天天气真好,阳光明 媚",
"userid": "1001",
"nickname": "Rose",
"createdatetime": new Date(),
"likenum": NumberInt(10),
"state": null
})
WriteResult({ "nInserted" : 1 })
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
如果collection集合不存在,则会隐式创建
注意:
mongo中的数字,默认情况下是double类型,如果要存储整型,必须使用函数NumberInt(整型数值),否则取出来就有问题。插入当前日期使用
new Date()。插入的数据没有指定
_id,会自动生成主键值。如果某字段没值,可以赋值为
null,或不写该字段。文档中的键/值对是有序的。
文档中的值不仅可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个文档)。
MongoDB区分类型和大小写。MongoDB的文档不能有重复的键。文档的键是字符串,除了少数例外情况,键可以使用任意UTF-8字符
文档中键的命名规范:
- 键不能含有\0(空字符)。这个字符用来表示键的结尾。
.和$有特殊的意义,只有在特定环境下才能使用。- 以下划线
_开头的键是保留的(不是严格要求的)
insertMany方法用于批量插入,语法:
db.collection.insertMany(
[ <document 1> , <document 2>, ... ],
{
writeConcern: <document>,
ordered: <boolean>
}
)
2
3
4
5
6
7
| Parameter | Type | Description |
|---|---|---|
document | document | An array of documents to insert into the collection. |
writeConcern | document | Optional. A document expressing the write concern (opens new window). Omit to use the default write concern.Do not explicitly set the write concern for the operation if run in a transaction. To use write concern with transactions, see Transactions and Write Concern (opens new window). |
ordered | boolean | Optional. A boolean specifying whether the mongod (opens new window) instance should perform an ordered or unordered insert. Defaults to true. |
示例:
#插入多条记录
db.article.insertMany([{
"_id": "1",
"articleid": "100001",
"content": "我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我 他。",
"userid": "1002",
"nickname": "相忘于江湖",
"createdatetime": new Date("2019-08- 05T22:08:15.522Z"),
"likenum": NumberInt(1000),
"state": "1"
}, {
"_id": "2",
"articleid": "100001",
"content": "我夏天空腹喝凉开水,冬天喝温开水",
"userid": "1005",
"nickname": "伊人憔 悴",
"createdatetime": new Date("2019-08-05T23:58:51.485Z"),
"likenum": NumberInt(888),
"state": "1"
}, {
"_id": "3",
"articleid": "100001",
"content": "我一直喝凉开水,冬天夏天都喝。",
"userid": "1004",
"nickname": "杰克船 长",
"createdatetime": new Date("2019-08-06T01:05:06.321Z"),
"likenum": NumberInt(666),
"state": "1"
}, {
"_id": "4",
"articleid": "100001",
"content": "专家说不能空腹吃饭,影响健康。",
"userid": "1003",
"nickname": "凯 撒",
"createdatetime": new Date("2019-08-06T08:18:35.288Z"),
"likenum": NumberInt(2000),
"state": "1"
}, {
"_id": "5",
"articleid": "100001",
"content": "研究表明,刚烧开的水千万不能喝,因为烫 嘴。",
"userid": "1003",
"nickname": "凯撒",
"createdatetime": new Date("2019-08- 06T11:01:02.521Z"),
"likenum": NumberInt(3000),
"state": "1"
}]);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
插入时指定了
_id,则主键为该键值。如果某条数据插入失败,将会终止插入,但已经插入成功的数据不会回滚。由于批量插入时数据量较大,容易出现失败,所以可以使用try catch进行异常捕捉处理。
# 查询
文档的查询方法有很多,先来了解以下两个方法:
db.collection.find(query, projection):在集合或视图上执行一个查询并返回一个cursor游标对象db.collection.findOne(query, projection):返回满足query条件的第一个文档
| Parameter | Type | Description |
|---|---|---|
query | document | 可选, 一个JSON对象用于筛选文档,如查找userId为1001的文档{userId:"10001"} |
projection | document | 可选,可以用于限定文档返回的键,{"articleid":1} |
示例:
#查询article集合中的所有文档
> db.article.find()
{ "_id" : ObjectId("5fed2b1b232584d8ba357db0"), "articleid" : "100000", "content" : "今天天气真好,阳光明 媚", "userid" : "1001", "nickname" : "Rose", "createdatetime" : ISODate("2020-12-31T01:36:27.784Z"), "likenum" : 10, "state" : null }
{ "_id" : "1", "articleid" : "100001", "content" : "我们不应该把清晨浪费在手机上,健康很重要,一杯温水幸福你我 他。", "userid" : "1002", "nickname" : "相忘于江湖", "createdatetime" : ISODate("1970-01-01T00:00:00Z"), "likenum" : 1000, "state" : "1" }
...
2
3
4
5
根据查询结果可以看到,当我只用insert方法插入时的文档中是没有指定_id字段的,但MongoDB会为每条文档自动创建该字段作类似于主键的标识,且生成类型为ObjectID类型的值。
#查询articleid为”10000“的文档
> db.article.find({articleid:"100000"})
{ "_id" : ObjectId("5fed2b1b232584d8ba357db0"), "articleid" : "100000", "content" : "今天天气真好,阳光明 媚", "userid" : "1001", "nickname" : "Rose", "createdatetime" : ISODate("2020-12-31T01:36:27.784Z"), "likenum" : 10, "state" : null }
#投影查询,限定文档返回的字段(_id字段会默认显示)
> db.article.find({article:"100000"},{articleid:1})
{ "_id" : ObjectId("5fed2b1b232584d8ba357db0"), "articleid" : "100000" }
> db.article.find({articleid:"100000"},{articleid:1,_id:0})
{ "articleid" : "100000" }
#查询所有数据,只显示`_id`、`userid`、`nickname`
> db.article.find({},{userid:1,nickname:1})
2
3
4
5
6
7
8
9
10
11
12
13
# 更新
文档的更新方法有:
db.collection.update()db.collection.updateOne()db.collection.updateMany()
update方法的语法:
db.collection.update(query,update,option)
或
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>,
collation: <document>,
arrayFilters: [ <filterdocument1>, ... ],
hint: <document|string> // Available starting in MongoDB 4.2
}
)
2
3
4
5
6
7
8
9
10
11
12
13
14
参数列表
| Parameter | Type | Description |
|---|---|---|
query | document | 更新条件,用于筛选出需要更新的文档。可以使用与find方法中相同的查询选择器,类似于where。在3.0版本中,当upsert:true执行update时。如果查询使用点表示法在_id字段上指定条件,则MongoDB将拒绝插入新的文档。 |
update | document or pipeline | 要应用的修改。该值可以是:包含更新运算符表达式的文档,或仅包含:对的替换文档,或在MongoDB 4.2中启动聚合管道。管道可以由以下阶段组成: |
upsert | boolean | 可选。如果设置为true,则在没有与查询条件匹配的文档时创建新文档。默认值为false,如果找不到匹配项,则不会插入新文档。 |
multi | boolean | 可选。如果设置为true,则更新符合查询条件的多个文档。如果设置为false,则更新一个文档。默认值为false。 |
writeConcern | document | 可选。表示写问题的文档。抛出异常的级别。 |
collation | document | 可选。Collation允许用户为字符串比较指定特定于语言的规则,例如字母和重音标记的规则。 |
arrayFilters | array | 可选的。筛选器文档的数组,用于确定要为对数组字段进行更新操作而修改哪些数组元素。 |
hint | Document or string | 可选。指定用于支持查询谓词的索引的文档或字符串。该选项可以采用索引规范文档或索引名称字符串。如果指定的索引不存在,则说明操作错误。例如,请参阅版本4中的“为更新操作指定提示。 |
主要关注前四个参数即可
示例:
覆盖的修改
将
_id为1的记录,点赞数量为1001:> db.article.update({_id:"1"},{likenum:NumberInt(1001)}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) > db.article.find({_id:"1"}) { "_id" : "1", "likenum" : 1001 }1
2
3
4结果是
update文档将原文档覆盖替换了,其它字段没有了。局部修改
为了解决上面的问题,需要使用修改器
$set来实现:> db.article.update({_id:"2"},{$set:{likenum:NumberInt(666)}}) WriteResult({ "nMatched" : 1, "nUpserted" : 0, "nModified" : 1 }) > db.article.find({_id:"2"}) { "_id" : "2", "articleid" : "100001", "content" : "我夏天空腹喝凉开水,冬天喝温开水", "userid" : "1005", "nickname" : "伊人憔 悴", "createdatetime" : ISODate("2019-08-05T23:58:51.485Z"), "likenum" : 666, "state" : "1" }1
2
3
4批量修改
更改所有用户名为
1003的用户的昵称为小明。# 默认只修改第一个文档(记录) > db.article.update({userid:"1003"},{$set:{nickname:"小明"}}) # 修改所有符合条件的数据 > db.article.update({userid:"1003"},{$set:{nickname:"小明"}},{multi:true})1
2
3
4
5列值增长的修改
如果想实现对某列值在原有值的基础上进行增加或减少,可以使用
$inc运算符来实现。db.article.update({_id:"3"},{$inc:{likenum:NumberInt(1)}})1
# 删除
删除文档的语法结构:
db.collection.remove(条件)
以下语句将会删除集合中全部的数据,慎用
db.collection.remove({})
# 更多查询
db.collection.count(query,options):统计查询Parameter Type Description querydocument 查询条件 optionsdocument 可选,用于修改计数的额外选项 #查询所有记录数 db.article.count() #统计`userid`为1003的记录数 db.article.count({userid:"10003"})1
2
3
4
5db.collection.find(<query>).limit(<number>):对find方法返回的coursor游标对象使用limit方法来指定返回文档的最大数量。默认为:20。#返回查询结果的前两个文档 db.article.find().limit(2)1
2db.collection.find(<query>).skip(<number>):在游标上调用skip()方法来控制MongoDB从哪里开始返回结果。这种方法在实现分页结果时可能很有用。#返回除前三个文档的所有文档 db.article.find().skip(3) #分页查询(第一页1,2,第二页3,4,第三页5) #跳过前两条数据,取3,4,返回第二页 db.article.find().skip(2).limit(2)1
2
3
4
5
6db.collection.find(<query>).sort({field: value}):指定查询返回匹配文档的顺序。并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而-1是用于降序排列。#对userid降序排列,并对访问量进行升序排列 db.article.find().sort({userid:-1,likenum:1})1
2skip(),limilt(),sort()三个放在一起执行的时候,执行的顺序是先sort(), 然后是skip(),最后是显示的limit(),和命令编写顺序无关。模糊查询,
MongoDB的模糊查询是通过正则表达式的方式实现的,格式为:db.article.find({field:/正则表达式/}) #查询评论内容包含"开水"的所有文档 db.article.find({content:/开水/}) #查询评论内容以“专家”开头的数据 db.article.find({content:/^专家/})1
2
3
4
5
6
7正则表达式是JS的语法,直接量的写法
比较查询
比较运算符对应的指令:
运算符 指令 <$lt<=$lte>$gt>=$gte!=$nedb.集合名称.find({"field":{$gt:value}}) //大于:field > value db.集合名称.find({"field":{$gte:value}}) //大于等于:field >= value db.集合名称.find({"field":{$lt:value}}) //小于:field < value db.集合名称.find({"field":{$lte:value}}) //小于等于:field <= value db.集合名称.find({"field":{$ne:value}}) //不等于:field != value #查询评论点赞数量大于666的数据 db.article.find({likenum:{$gt:NumberInt(666)}})1
2
3
4
5
6
7
8包含查询,使用
$in指令#查询userid包含1002、1003的文档 db.article.find({userid:{$in:["1003","1002"]}})1
2不包含使用
$nin指令条件查询
与运算,查询同时满足两个以上的条件,需要使用
$and指令将条件进行连接:$and:[{},{},{}] #查询评论集合中点赞数likenum大于等于666且小于2000的文档 db.article.find({$and:[{likenum:{$gte:NumberInt(666)}},{likenum:{$lt:NumberInt(2000)}}]},{likenum:1})1
2
3
4或运算,使用
$or指令,格式与$and指令类似$or:[{},{},{}]1
# 常用命令小结
#选择切换数据库:
use articledb
#插入数据:
db.comment.insert({bson数据})
#查询所有数据:
db.comment.find();
#条件查询数据:
db.comment.find({条件})
#查询符合条件的第一条记录:
db.comment.findOne({条件})
#查询符合条件的前几条记录:
db.comment.find({条件}).limit(条数)
#查询符合条件的跳过的记录:
db.comment.find({条件}).skip(条数)
#修改数据:
db.comment.update({条件},{修改后的数据})
或
db.comment.update({条件},{$set:{要修改部分的字段:数据})
#修改数据并自增某字段值:
db.comment.update({条件},{$inc:{自增的字段:步进值}})
#删除数据:
db.comment.remove({条件})
#统计查询:
db.comment.count({条件})
#模糊查询:
db.comment.find({字段名:/正则表达式/})
#条件比较运算:
db.comment.find({字段名:{$gt:值}})
#包含查询:
db.comment.find({字段名:{$in:[值1,值2]}})
或
db.comment.find({字段名:{$nin:[值1,值2]}})
#条件连接查询:
db.comment.find({$and:[{条件1},{条件2}]})
或
db.comment.find({$or:[{条件1},{条件2}]})
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
# 四、索引(Index)
索引支持在MongoDB中高效地执行查询。如果没有索引,MongoDB必须执行全集合扫描,即扫描集合中的每个文档,以选择与查询语句匹配的文档。这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
如果查询存在适当的索引,MongoDB可以使用该索引限制必须检查的文档数。
索引是特殊的数据结构,它以易于遍历的形式存储集合数据集的一小部分。索引存储特定字段或一组字段的值,按字段值排序。索引项的排序支持有效的相等匹配和基于范围的查询操作。此外,MongoDB还可以使用索引中的排序返回排序结果。
MongoDB索引使用B树数据结构(确切的说是B-Tree,MySQL是B+Tree)
# 索引的类型
# 单字段索引
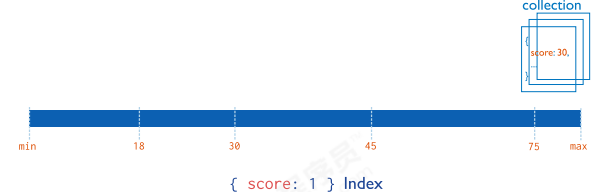
MongoDB支持在文档的但个字段上创建用户定义的升序/降序索引,称为单字段索引(Single Field Index)。
对于单个字段索引和排序操作,索引键的排序顺序(即升序或降序)并不重要,因为MongoDB可以在任何方向上遍历索引。
# 复合索引
MongoDB还支持多个字段的用户定义索引,即复合索引(Compound Index)。
复合索引中列出的字段顺序具有重要意义。例如,如果复合索引由{userid:1,score:-1}组成,则索引首先按userid正序排序,然后在每个userid的值内,再按scroe倒序排序。

# 其他索引
- 地理空间索引(
Geospatial Index):为了支持对地理空间坐标数据的有效查询,MongoDB提供了两种特殊的索引:返回结果时使用平面几何的二维索引和返回结果时使用球面几何的二维球面索引。 - 文本索引(Text Indexes):
MongoDB提供了一种文本索引类型,支持在集合中搜索字符串内容。这些文本索引不存储特定于语言的停止词(例如"the"、"a"、"or"),而将集合中的词作为词干,只存储根词。 - 哈希索引(Hash Indexes):为了支持基于散列的分片,
MongoDB提供了散列索引类型,它对字段值的散列进行索引。这些索引在其范围内的分布更加随机,但只支持相等匹配,不支持基于范围的查询。
# 索引的管理
db.collection.getIndexes():查看集合中所有索引的数组。该命令运行要求是MongoDB 3.0+。> db.article.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" } ]1
2结果中显示的是默认
_id索引。主键默认会创建唯一值索引。v代表的是索引引擎的版本号。key表示加了索引的字段_id,值1表示升序。name表示索引的名称,默认的方式是索引字段名称后面加下划线。ns表示命名空间,通常是数据库+集合名称。MongoDB在创建集合的过程中,在_id字段上创建一个唯一的索引,默认名字为_id_,该索引可防止客户端插入两个具有相同值的文档,不能再_id字段上删除此索引。该索引是唯一索引,因此值不能重复,即
_id值不能重复,在分片集群中通常使用_id作为片键。db.collection.createIndex(keys,options):在集合上创建索引参数
param type description keysdocument 包含字段和值对的文档,其中字段是索引键,值描述该字段的索引类型。对于字段上的升序索引,请指定值1;对于降序索引,请指定值-1。比如: {字段:1或-1} ,其中1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。另外,MongoDB支持几种不同的索引类型,包括文本、地理空间和哈希索引。 optionsdocument 可选。包含一组控制索引创建的选项的文档。有关详细信息,请参见选项详情列表。 常用
options选项:param type description background boolean 建索引过程会阻塞其它数据库操作,background可以指定以后台方式创建索引,默认为false unique boolean 建立的索引是否唯一,指定为true创建唯一索引,默认为false name string 索引名称。 weights document 索引的权重,数值在1到99999之间,表示该索引相对其他索引字段的得分权重 在 3.0.0 版本前创建索引方法为
db.collection.ensureIndex(),之后的版本使用了db.collection.createIndex()方法,ensureIndex()还能用,但只是createIndex()的别名。示例:
> db.article.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" } ] #单字段索引,对userid字段按升序建立索引 > db.article.createIndex({userid:1}) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 1, "numIndexesAfter" : 2, "ok" : 1 } #复合索引,对userid字段升序和nickname字段降序建立符合索引 > db.article.createIndex({userid:1,nickname:-1}) { "createdCollectionAutomatically" : false, "numIndexesBefore" : 2, "numIndexesAfter" : 3, "ok" : 1 } > db.article.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" }, { "v" : 2, "key" : { "userid" : 1 }, "name" : "userid_1" }, { "v" : 2, "key" : { "userid" : 1, "nickname" : -1 }, "name" : "userid_1_nickname_-1" } ]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45db.collection.dropIndex(index):移除指定索引param type description index string or document 指定要删除的索引。可以通过索引名称或索引规则文档指定索引,若删除文本索引,请指定索引名称。 示例:
> db.article.dropIndex("userid_1") { "nIndexesWas" : 3, "ok" : 1 } > db.article.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" }, { "v" : 2, "key" : { "userid" : 1, "nickname" : -1 }, "name" : "userid_1_nickname_-1" } ]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20db.collection.dropIndexes():移除集合中所有索引(除了默认_id_索引)> db.article.dropIndexes() { "nIndexesWas" : 2, "msg" : "non-_id indexes dropped for collection", "ok" : 1 } > db.article.getIndexes() [ { "v" : 2, "key" : { "_id" : 1 }, "name" : "_id_" } ]1
2
3
4
5
6
7
8
# 索引的使用
# 执行计划
分析查询性能(Analyze Query Performance)通常使用执行计划(解释计划、Explain Plan)来查看查询的情况,如查询耗费的时间,是否基于索引查询等。
应用场景:查看建立的索引是否有效?效率如何?
语法:db.collection.find(query,option).explain(options)
示例:
> db.article.find({userid:"1003"}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "meface.article",
"indexFilterSet" : false,
"parsedQuery" : {
"userid" : {
"$eq" : "1003"
}
},
"queryHash" : "37A12FC3",
"planCacheKey" : "37A12FC3",
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"userid" : {
"$eq" : "1003"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "u20",
"port" : 27017,
"version" : "4.4.2",
"gitVersion" : "15e73dc5738d2278b688f8929aee605fe4279b0e"
},
"ok" : 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
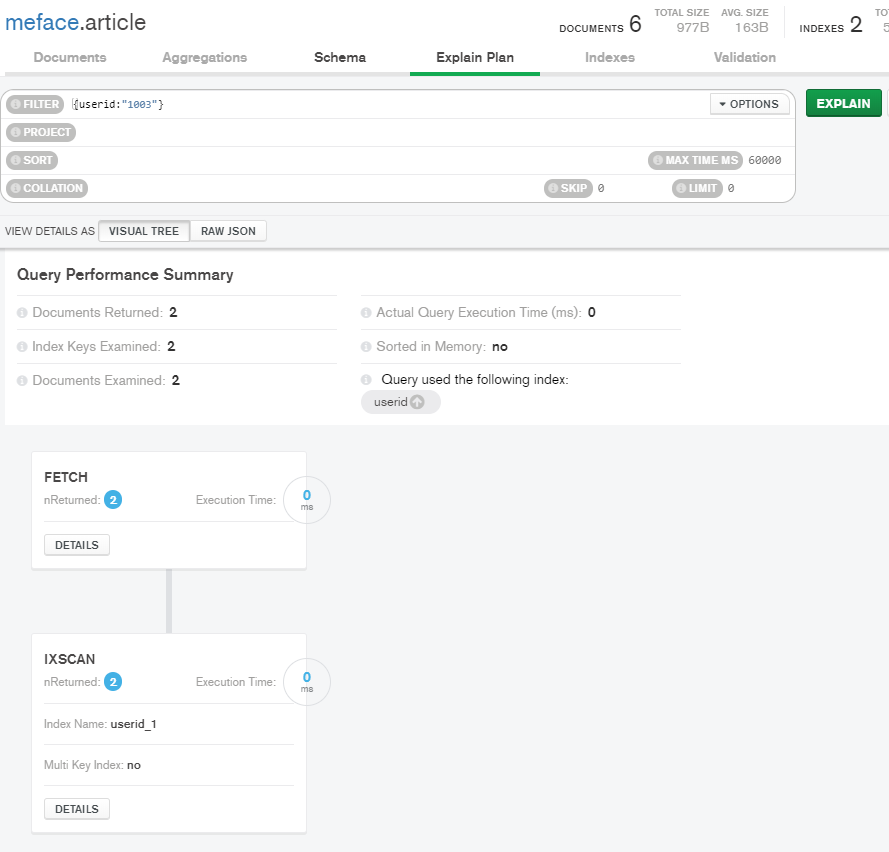
可以看到winningPlan中的stage是COLLSCAN(集合扫描),说明没有使用索引。
下面创建userid索引,再执行计划:
> db.article.createIndex({userid:1})
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}
> db.article.find({userid:"1003"}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "meface.article",
"indexFilterSet" : false,
"parsedQuery" : {
"userid" : {
"$eq" : "1003"
}
},
"queryHash" : "37A12FC3",
"planCacheKey" : "7FDF74EC",
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"userid" : 1
},
"indexName" : "userid_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"userid" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"userid" : [
"[\"1003\", \"1003\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "u20",
"port" : 27017,
"version" : "4.4.2",
"gitVersion" : "15e73dc5738d2278b688f8929aee605fe4279b0e"
},
"ok" : 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
可以看到stage是IXSCAN,基于索引的扫描。
在可视化工具compass中,可以更加清除的查看到。先从索引集合中扫描,抓取匹配的文档。
# 涵盖查询
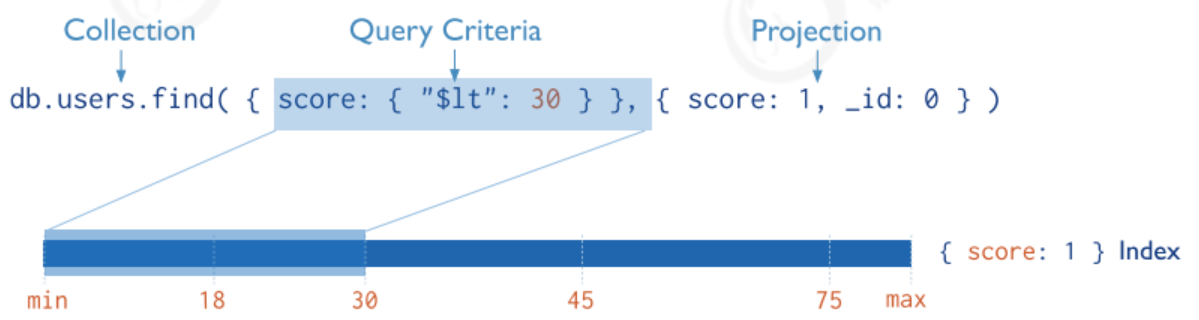
涵盖查询(Covered Queries):当查询条件和查询的投影仅包含索引字段时,MongoDB直接从索引返回结果,而不扫描任何文档或将文档带入内存。这些覆盖的查询可以非常的有效。
示例:
> db.article.find({userid:"1003"},{userid:1,_id:0})
{ "userid" : "1003" }
{ "userid" : "1003" }
> db.article.find({userid:"1003"},{userid:1,_id:0}).explain()
{
"queryPlanner" : {
"plannerVersion" : 1,
"namespace" : "meface.article",
"indexFilterSet" : false,
"parsedQuery" : {
"userid" : {
"$eq" : "1003"
}
},
"queryHash" : "8177476D",
"planCacheKey" : "B632EADC",
"winningPlan" : {
"stage" : "PROJECTION_COVERED",
"transformBy" : {
"userid" : 1,
"_id" : 0
},
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"userid" : 1
},
"indexName" : "userid_1",
"isMultiKey" : false,
"multiKeyPaths" : {
"userid" : [ ]
},
"isUnique" : false,
"isSparse" : false,
"isPartial" : false,
"indexVersion" : 2,
"direction" : "forward",
"indexBounds" : {
"userid" : [
"[\"1003\", \"1003\"]"
]
}
}
},
"rejectedPlans" : [ ]
},
"serverInfo" : {
"host" : "u20",
"port" : 27017,
"version" : "4.4.2",
"gitVersion" : "15e73dc5738d2278b688f8929aee605fe4279b0e"
},
"ok" : 1
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
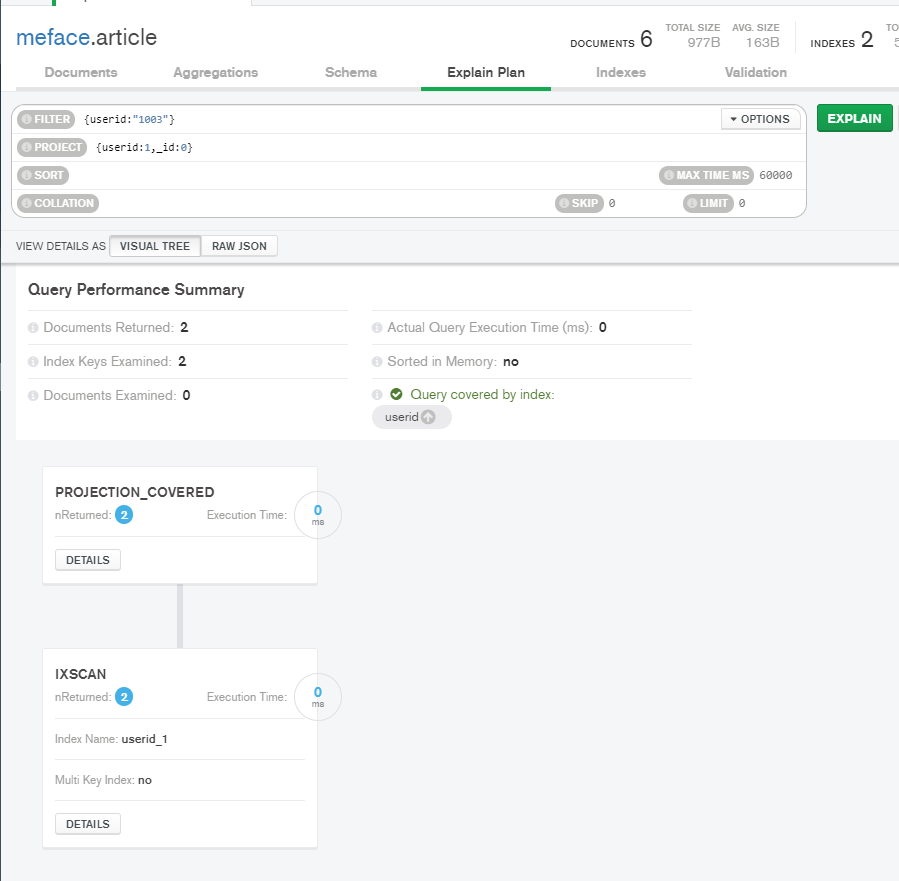
在compass工具中查看,Query covered by index只查询了索引的集合。
# 参考文档
[1] Collection Methodshttps://docs.mongodb.com/manual/reference/method/js-collection/
[2] Cursor Methods https://docs.mongodb.com/manual/reference/method/js-cursor/
[3] MongoDB CRUD Operations https://docs.mongodb.com/manual/crud/
[4] Indexes https://docs.mongodb.com/manual/indexes/
[5] MongoDB基础入门到高级进阶 https://www.bilibili.com/video/BV1j541187bA